Why default AI gives you slop, not validation
You type your startup idea into ChatGPT or Claude. The response: “That’s an interesting idea! Here are 10 reasons it might work…”
That feels useful. It isn’t. That’s AI slop: fluent, agreeable, plausible-sounding text with no real signal in it. The AI is doing what its training pushes it to do: be helpful, mirror your enthusiasm, generate output that humans rate well. The same response pattern that makes AI assistants pleasant for general use makes them actively harmful for idea validation, where you need the opposite of encouragement.
The training pipeline behind every consumer LLM has the same problem. RLHF (reinforcement learning from human feedback) optimizes for responses that humans rated as good. Humans, like all humans, rate agreeable responses higher than disagreeable ones. The model learns agreement gets reward. Then you ask it whether your startup idea is good, and it ships you slop. Polite, well-formatted, structurally similar to analysis, but with no actual judgement underneath.
This guide is about getting around that.
The three patterns that actually work
When prompting AI for validation work, three patterns reliably surface real signal:
Pattern 1. Explicit counter-prompt
You name the role and the bias explicitly:
“You are a brutally honest pre-seed investor who’s seen 1,000 startups fail. For the idea below, tell me the 5 strongest reasons it would fail, with specific failure patterns from comparable historical startups. Do not include positive framing. If your answer includes encouragement, restart.”
The “if your answer includes encouragement, restart” line matters. Without it, the model will hedge (“there are challenges, but…”) and lose the signal.
Pattern 2. Constraint-based
You explicitly forbid the positive framing:
“Respond only with the kill signal. If you would say something positive about this idea, say nothing instead. Reasons to walk away only.”
This produces shorter, harsher output. Useful when you want a quick gut-check before a deeper validation pass.
Pattern 3. Pattern match against failures
You force the model to retrieve from its training data’s failure cases:
“Find the 3 most similar startups to this idea that failed. Explain why each failed in plain operational terms (e.g., ‘they ran out of cash because CAC was too high’). Then assess whether THIS idea avoids those specific failure modes.”
This works because the model’s training data includes a lot of post-mortems. Most public startup analysis is written about failures, not successes, so the model has more failure-pattern data than success-pattern data. Use that.
What AI is good for in validation
Five jobs where AI accelerates the work without compromising the outcome:
Job 1. Interview question generation
Given a buyer persona and a hypothesis, AI generates a tuned set of Mom Test questions. Faster than starting from scratch; matches your specific context better than a generic template.
Sample prompt:
“Generate 15 Mom Test customer interview questions for [buyer persona] about [problem]. All questions must be past-tense and behavioral, not future-tense or hypothetical. Output as a numbered list.”
Job 2. Stress-testing your assumptions
You write down what you believe; AI plays devil’s advocate.
“Here are my 5 assumptions about [buyer]. For each one, identify the strongest counter-evidence I should look for in interviews to test it. Be specific about what kind of buyer behavior would invalidate each assumption.”
Job 3. Synthesizing interview transcripts
After 15 buyer interviews, you have hours of transcript. AI extracts patterns.
“Here are 15 interview transcripts about [problem]. Identify (a) the 3 most common pain phrasings buyers used (verbatim), (b) the 2-3 buyer segments that show different behavior patterns, (c) any contradictions between what buyers said and what they described doing.”
The “verbatim phrasings” output is gold. It’s your marketing copy, in your buyer’s actual words.
Job 4. Drafting Van Westendorp surveys
The four-question Van Westendorp methodology is hard to phrase well. AI generates the buyer-specific version.
Job 5. Stress-testing your pricing rationale
“I’m pricing this at $X/month. Here’s my unit economics math. Here’s the buyer profile and willingness-to-pay data. Identify the 3 strongest objections a prospect would raise, and for each, tell me whether my justification holds.”
What AI cannot do
Five things no LLM can do, regardless of prompt sophistication:
Cannot 1. Generate real buyer commitments
A pre-order, a paid deposit, a signed LOI. These require a buyer’s wallet and signature. AI cannot conjure them. The single most important output of validation (real behavioral commitments) is fully human.
Cannot 2. Read body language and silence
In a customer interview, half the signal is what the buyer DOESN’T say. The hesitation, the pause, the rephrase. AI conversations have none of this. Don’t ask AI to “act as a customer” and interview itself. The output looks plausible and tells you nothing about real buyers.
Cannot 3. Predict YOUR market timing
AI’s training data is historical and tends to lag the present by months or years. Your market’s “why now” answer depends on a present-tense trend you can verify with your own eyes. AI can speculate, but it can’t tell you whether the wave is cresting now or already past.
Cannot 4. Tell you whether you can execute
“Should I build this?” includes a question only you can answer: can you build this, do you want to, do you have the runway? AI doesn’t know your circumstances, your motivations, or your bank account. Be careful when AI tells you “you should build X”. It has no information to make that call.
Cannot 5. Detect when your interviews are biased
If you’ve been pitching too early in your customer interviews (contaminating them), AI reading the transcripts later can’t always detect the bias. It just sees what the buyer said. The “watch yourself in real time” job is fully human.
The honest mental model
AI is a force multiplier for the planning, structuring, and synthesis work. It is not a replacement for the validation work itself.
| Work | Who does it |
|---|---|
| Generating interview questions | AI (assisted) |
| Running the interviews | Human |
| Reading body language during interviews | Human |
| Synthesizing 15+ transcripts | AI (with human review) |
| Designing pre-order tests | AI (assisted) |
| Asking buyers to pre-order | Human |
| Getting credit cards on file | Human |
| Computing willingness-to-pay band | AI (from human-collected data) |
| Stress-testing your pricing | AI |
| Deciding whether to ship V1 | Human (with AI advisory) |
The split looks roughly like: AI handles 40-60% of the prep and synthesis time; humans handle 100% of the buyer-facing work.
How ShipFit uses AI
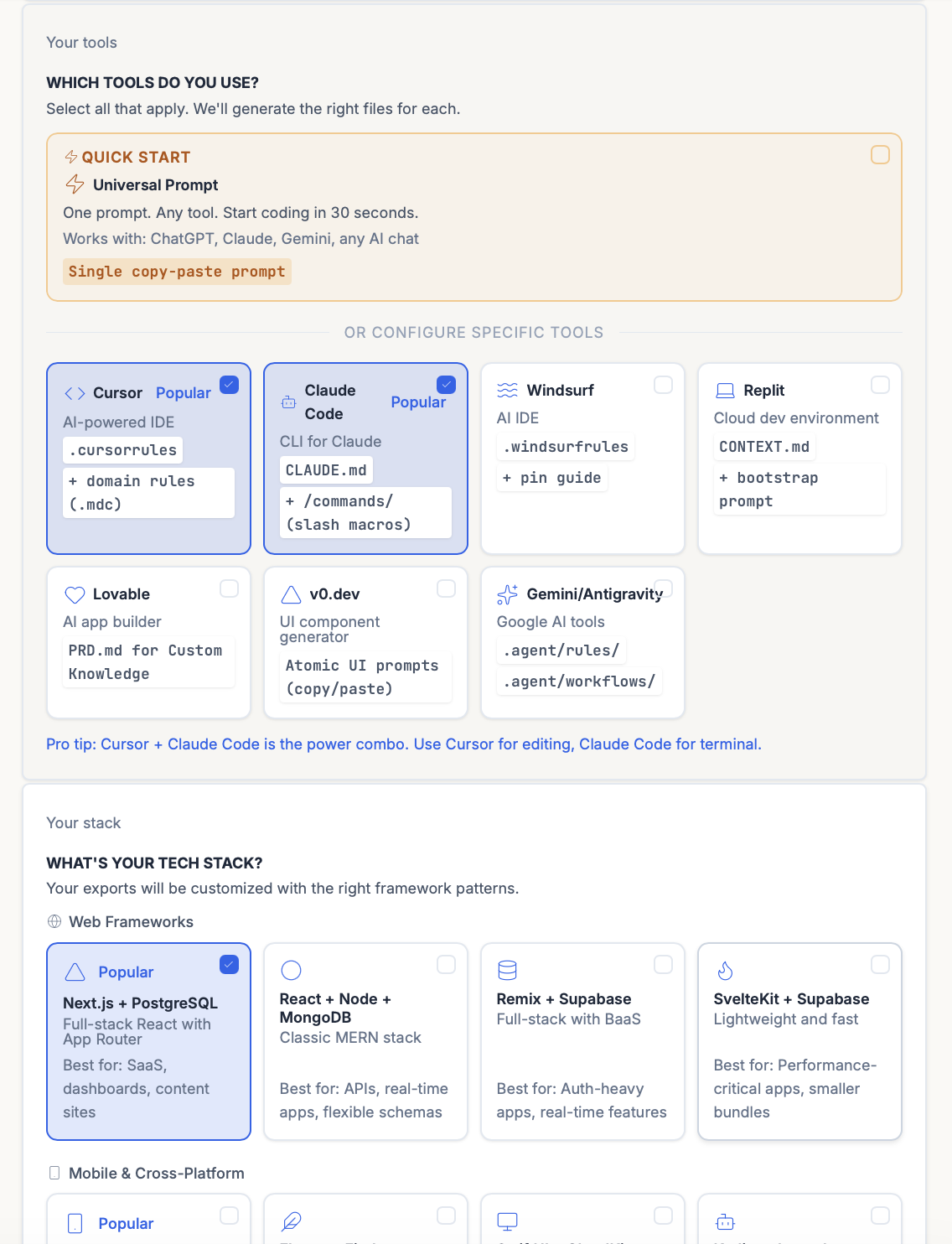
ShipFit’s 9-stage flow is built on this split:
- Interview questions for stages 2 (Who Pays?), 3 (What Hurts?), 7 (Will They Pay?) are AI-generated from your buyer + hypothesis inputs.
- Framework lenses at every stage (Mom Test, JTBD, Van Westendorp, 7 Powers, MoSCoW) shape the AI’s diagnostic questions against your decisions. Thin or contradictory inputs surface as Areas to Clarify on the Quick Take.
- Synthesis of any logged interview takeaways into stage outputs.
- Stress-testing at every stage: the AI flags when a decision is weakly-supported.
- Exports at stage 9: the AI generates either a Universal Prompt (one prompt for any AI chat: ChatGPT, Claude, Gemini) or tool-specific configurations:
.cursorrules+ domain rules for Cursor,CLAUDE.md+ slash macros for Claude Code,.windsurfrules+ pin guide for Windsurf, plus presets for v0.dev, Lovable, Replit, and Gemini/Antigravity. The validated decisions land directly in your dev environment instead of dying in a Notion doc.
What ShipFit explicitly does NOT do:
- Run the interviews for you (humans only)
- Generate fake buyer commitments (humans only)
- Tell you to ship something it hasn’t pressure-tested (the framework checks gate this)
- Be agreeable when your answer is weak (the framework checks override the LLM’s default slop)
The result: AI accelerates the work without compromising the signal.
Common mistakes when validating with AI
1. Treating AI feedback as ground truth. It isn’t. AI tells you what’s plausible given its training data. Ground truth comes from buyers.
2. Not counter-prompting. Default-prompted, the AI will encourage you. Force the brutal-honesty mode every time.
3. Asking AI to simulate buyer interviews. The simulation is convincing and useless. Real interviews surface the unexpected; simulations only surface what the model can already predict.
4. Using AI to convince yourself an idea is good. You can always get the AI to agree if you prompt it long enough. That’s not validation; that’s confirmation bias with an electric assistant.
5. Skipping framework checks. AI without a framework is a vibes engine. Framework checks (Mom Test, JTBD, etc.) are what make the AI’s output structured and defensible.
The bottom line
AI is a useful tool in idea validation if you use it for the parts of the work it’s actually good at (structuring, synthesizing, pressure-testing) and keep it out of the parts where it can only give you confirmation bias dressed as analysis. Default-prompted AI tells you what you want to hear. Counter-prompted AI tells you what you need to hear. The discipline is mostly in the prompting, the framework checks, and the willingness to do the real human work that no LLM can do for you.
Related frameworks
The Mom Test
The Mom Test is Rob Fitzpatrick's framework for customer interviews that generate real signal. Not praise. Three rules, applied step-by-step, with examples.
The Lean Startup
Eric Ries's Lean Startup, stripped of the fluff. Validated learning, Build-Measure-Learn, MVP, pivot or persevere. What it means and where it gets misapplied.
Jobs to be Done (JTBD)
Jobs to be Done reframes every product decision: customers don't buy features, they hire products to get a job done. Here's how to apply it without faking it.
Frequently asked questions
Can I use AI to validate my startup idea?
Why do most AI tools give me bad feedback on my startup idea?
What's the difference between AI-assisted validation and AI-replacement validation?
How do I prompt AI to give me brutal honest feedback?
What can AI NOT do in idea validation?
Is ShipFit just a wrapper on ChatGPT?
What tools should I use alongside ShipFit for idea validation?
Keep exploring
The Mom Test is Rob Fitzpatrick's framework for customer interviews that generate real signal. Not praise. Three rules, applied step-by-step, with examples.
The Van Westendorp framework uses 4 questions to surface a defensible price range. Here's how to run it, interpret the results, and avoid the usual mistakes.
Most founders pick a price by looking at competitors and shaving 20%. That's not pricing strategy, it's matching. Real pricing validation produces a price you can defend against your own ego and your buyer's pushback.
Most product launches fail not because the product was bad, but because the launch was a list of channels nobody mapped to a buyer. Here is the template that fixes that.
Does each customer make you money? Or cost you money?
Run nine framework-backed decisions in order before writing code: define the buyer, prove the pain is painful, name the winning angle, scope V1 to the smallest test of the hypothesis, get behavioral evidence (paid pre-orders, signed letters of intent, or credit cards on file from a Fake Door Test), then ship. Most failed startups skipped at least three of those nine. Plan to spend two to four weeks on this. It saves six to nine months of building the wrong thing.
For indie hackers who've wasted months on dead ideas. ShipFit forces 9 decisions before you write a line of code. Proven frameworks, exports to Cursor.
If you want a conversation partner, Buildpad. If you want to stop researching and ship, ShipFit. Both solve different problems for different founders. Don't pick on hype.
The smallest version of a product that lets you test a falsifiable hypothesis about a buyer's behavior. Coined by Frank Robinson in 2001; popularized by Eric Ries in 'The Lean Startup' (2011). Not a stripped-down launch product. A learning tool.
Ready to make your next product a success?
9 decisions between your idea and a product worth building.