The MVP that wasn’t
The most expensive mistake in startup history isn’t building the wrong product. It’s building the right product but at version 1.3 instead of version 1.
The founder who knows what to build but ships the polished, feature-complete, “ready” version of it 6 months late has lost the same battle as the founder who built the wrong thing. They’ve burned the runway, they’ve missed the market timing, and they’ve never tested the hypothesis that V1 was supposed to test.
This guide is the scoping discipline that prevents that.
The one rule of MVP scoping
For every feature you’re considering for V1, ask: “If we ship without this, does the hypothesis still get tested?”
If the answer is yes, the feature isn’t Must. It’s Should-Have or Could-Have. It belongs in V2 or V3, not V1.
If the answer is no. Without this feature, we genuinely cannot tell whether buyers will pay. The feature is Must. It ships in V1.
The trap is that founders feel everything is a Must because everything sounds useful. “Users will want X” is true for almost every X. The relevant question isn’t “would users want this?” It’s “does the absence of this prevent us from testing whether the business works?”
The MoSCoW gate
Dai Clegg’s 1994 MoSCoW framework gives you four buckets:
- 1Bucket 1
Must
V1 cannot ship without this.
The hypothesis cannot be tested without this feature. For a typical SaaS MVP the Must list should hold 3-5 features. If you have 8+ Musts, you have already failed at MoSCoW; revisit each one with the "is this required to test the hypothesis?" gate.
- 2Bucket 2
Should
V1 is meaningfully worse without this, but the hypothesis can still be tested.
Items here are V1.5 candidates. Ship them if effort is low; otherwise hold for the next release.
- 3Bucket 3
Could
Nice to have, doesn't affect the hypothesis test.
Default to V2. The cost of building Could-haves in V1 isn't the build time; it's the dilution of focus on the Musts.
- 4Bucket 4 · Most overlooked
Won't
Explicitly out of scope for V1.
Naming what you are explicitly choosing not to build is half the discipline. Most teams skip this bucket and end up building Should-haves they could have skipped, then ship V1 late and confused.
The impact-effort matrix
Once you have a candidate Must list, score each feature on two axes:
Impact (1-10): how much does this feature move the hypothesis test? Effort (1-10): how many engineer-days to build it?
Plot them:
| Effort \ Impact | High impact | Low impact |
|---|---|---|
| Low effort | V1 (build first) | Skip or V3 |
| High effort | V1 only if hypothesis-blocking; else V2 | V4 / never |
The “high effort, low impact” quadrant is where most MVPs go to die. Engineers love these features because they’re technically interesting. Founders sign off because the feature “felt important.” Six months later, V1 ships with a beautifully-architected feature that didn’t move the conversion needle.
The fix: be brutal about the impact score. If you can’t articulate in one sentence how the feature changes the hypothesis test, the impact is below 5.
The ICE-scoring version
ICE scoring is the numerical version of the matrix:
ICE = Impact × Confidence × Ease
For each feature:
- Impact: how much does this move the metric (1-10)
- Confidence: how sure are you about the impact (1-10)
- Ease: how easy to build (1-10, where 10 is easiest)
Multiply. Rank. Cut the bottom 60%. The remaining 40% is V1.
The gotcha: founders inflate Confidence for pet projects. Run ICE with a co-founder or a brutal advisor. If Confidence is 9 but you can’t name three pieces of evidence supporting it, the real Confidence is 4.
What to polish vs. leave rough
V1 has finite polish budget. Spend it where the buyer’s first impression forms:
Polish:
- Landing page (this is where conversion is won or lost)
- Signup flow
- The one core “aha moment” interaction
- Pricing page
Leave rough (and the world won’t end):
- Admin / settings pages
- Edge-case error states
- Integrations beyond the primary 1-2
- Mobile responsiveness (if your buyer is desktop-first)
- Onboarding email sequences beyond the first welcome
The mistake most founders make: they polish the admin dashboard their internal team uses and ship a confusing signup flow. The signup flow loses 60% of would-be converts on the first session. The admin dashboard nobody sees doesn’t matter.
Scope creep. Three early warning signs
Once V1 scope is locked, watch for these:
-
The Must list grows during the build. This is fatal. V1 scope should ONLY shrink (when you discover something is harder than estimated and you cut it), never grow. New great ideas go to a V2 file, not into V1.
-
Sprint reviews include “we also did X.” Engineers building features that weren’t planned is a process problem. Catch it in the first sprint and don’t let it pattern-set.
-
Launch date moves back by 1-2 weeks every 2 weeks. This is the death spiral. Each delay enables more “while we’re at it” additions, which cause more delays. Break the spiral by hard-locking the launch date and cutting features instead.
The Lean Startup connection
Eric Ries’s Lean Startup framework (2011) introduced the “build-measure-learn” loop. The MVP is the smallest build that enables one measure-learn cycle.
The two most-cited MVP examples in the book are deliberately tiny:
- Dropbox. Drew Houston’s MVP was a 3-minute video explaining what the product would do. It tested whether the demand was real (it was. The beta waitlist exploded). No actual file-sync product was built for the MVP test.
- Zappos. Nick Swinmurn’s MVP was buying shoes from local stores when orders came in. It tested whether people would buy shoes online (they would). No inventory was built for the MVP test.
Both validated the hypothesis at near-zero engineering cost. Both were embarrassingly small. Both worked.
The lesson isn’t to literally build a video as your MVP (the bar is higher now). The lesson is: name the hypothesis V1 tests, then strip everything that isn’t required to test it.
Common mistakes
1. Calling everything a Must. If your Must list has 12 items, you’re not scoping. You’re listing.
2. Polishing the wrong things. Polish the conversion path. Leave the admin tools rough.
3. No locked V1 scope. If V1 isn’t written on a wall before build starts, scope will creep. Lock it.
4. Building before defining the hypothesis. “What does V1 prove?” should have a one-sentence answer before any code gets written. If it doesn’t, you’re not building an MVP, you’re building a product hoping someone will buy it.
5. Treating the MVP as the eventual product. V1 tests the hypothesis. V2 is the product. Mixing the two means V1 is too ambitious and V2 never gets the focus it needs.
What ShipFit does at this stage
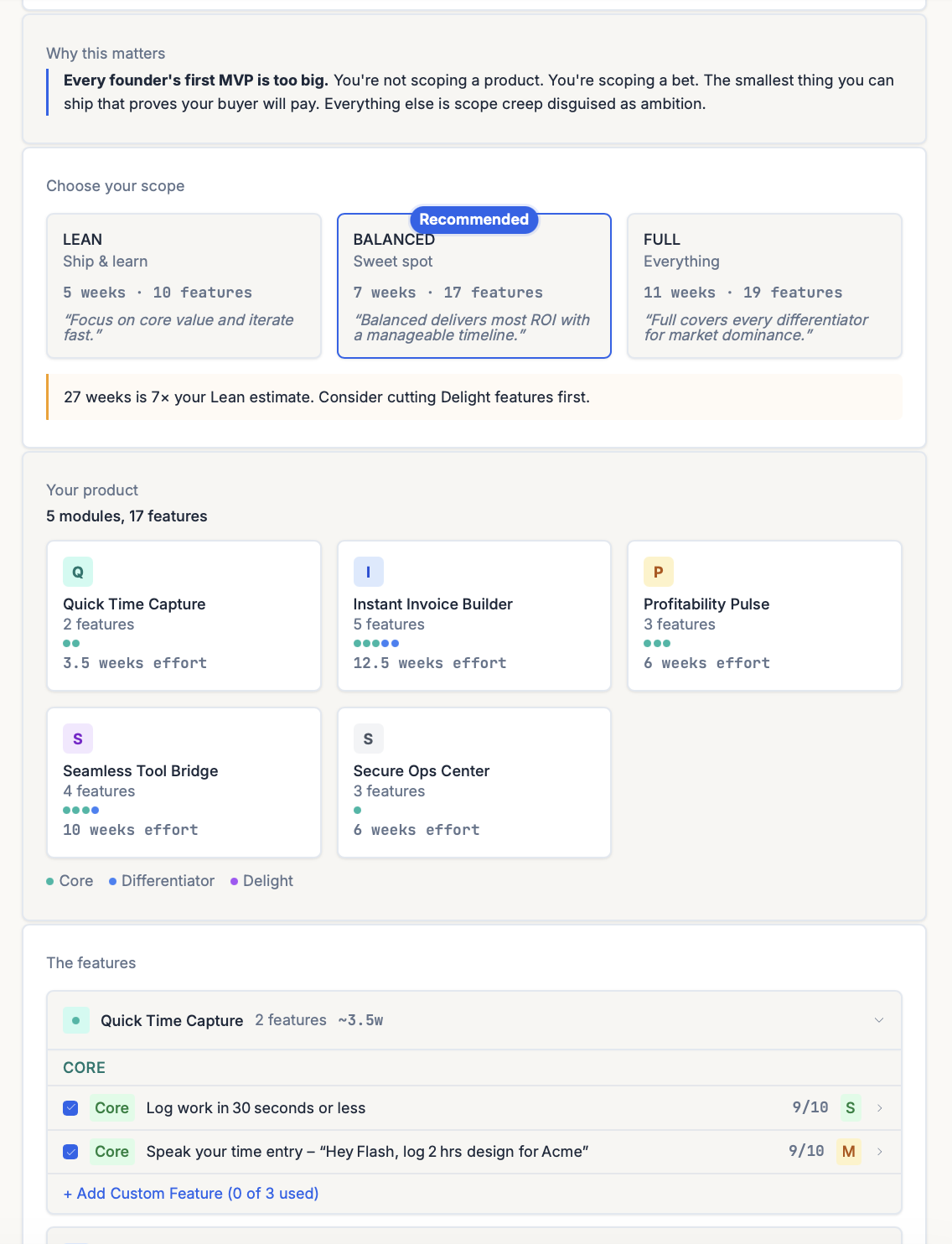
Stage 5 of the 9-step playbook is What’s V1?. The output is your MVP scope, sorted into three buckets:
| Bucket | What goes here | Cut rule |
|---|---|---|
| DIFFERENTIATOR | The 3-5 features that make the buyer pick you over the incumbent. “Why you pick us over the other guy. This is your bet.” | Keep all. |
| DELIGHT | Features users will love but can’t afford yet. “Cut first.” | Most of these go to V2. |
| OPERATIONAL | The plumbing required to make the Differentiators work (auth, billing, basic admin). | Keep the minimum. |
Each feature carries an ICE-style score (0-10) plus an effort tag (S/M/L), so the cut decisions are visible instead of vibes. The “Cut first” instruction on Delight is deliberate: it’s the single most-resisted feedback ShipFit gives, and the single most-validated way to ship in 4-8 weeks instead of 6 months.
Under the hood:
- Your feature wishlist gets parsed and each feature dropped into one of the three buckets.
- MoSCoW and ICE lenses applied to each feature against the V1 hypothesis you wrote.
- Output is three MVP packages — Lean, Balanced, Full — so you can see the scope/effort tradeoff explicitly before you pick.
- Deferred items (Delights, Shoulds, Coulds) land in a V2 file with effort tags, so the cut features are parked instead of lost.
The output drops into your dev environment via Q9 exports: Universal Prompt for any AI chat, or tool-specific configs for Cursor + Claude Code + Windsurf + v0 + Lovable + Replit + Gemini. So the scope discipline survives the handoff to engineering.
The bottom line
MVP scoping isn’t about being minimal for minimal’s sake. It’s about being scoped enough to test one hypothesis, fast enough to learn before runway runs out, and disciplined enough to cut everything that doesn’t serve that test. Most products fail because their V1 was actually V1.3. Don’t build that one.
Related frameworks
MoSCoW
MoSCoW prioritization scopes V1 by sorting features into Must, Should, Could, and Won't. The honest version cuts ruthlessly and ships in weeks, not months.
ICE Scoring
ICE Scoring multiplies Impact × Confidence × Ease to rank features and experiments. The honest version forces you to defend Confidence with hard evidence.
The Lean Startup
Eric Ries's Lean Startup, stripped of the fluff. Validated learning, Build-Measure-Learn, MVP, pivot or persevere. What it means and where it gets misapplied.
Frequently asked questions
What is an MVP?
How do I decide what features make it into V1?
What's the impact-effort matrix and how does it apply to MVP scope?
How long should an MVP take to build?
Should the MVP be polished or rough?
What's the difference between an MVP and a prototype?
How do I know when MVP scope creep is happening?
Keep exploring
MoSCoW prioritization scopes V1 by sorting features into Must, Should, Could, and Won't. The honest version cuts ruthlessly and ships in weeks, not months.
The Mom Test is Rob Fitzpatrick's framework for customer interviews that generate real signal. Not praise. Three rules, applied step-by-step, with examples.
Most early-stage competitive analysis is a 2x2 with your product in the top-right quadrant. The real version is harder, more boring, and tells you whether you can actually win.
Most founders pick a price by looking at competitors and shaving 20%. That's not pricing strategy, it's matching. Real pricing validation produces a price you can defend against your own ego and your buyer's pushback.
Does each customer make you money? Or cost you money?
Run nine framework-backed decisions in order before writing code: define the buyer, prove the pain is painful, name the winning angle, scope V1 to the smallest test of the hypothesis, get behavioral evidence (paid pre-orders, signed letters of intent, or credit cards on file from a Fake Door Test), then ship. Most failed startups skipped at least three of those nine. Plan to spend two to four weeks on this. It saves six to nine months of building the wrong thing.
For indie hackers who've wasted months on dead ideas. ShipFit forces 9 decisions before you write a line of code. Proven frameworks, exports to Cursor.
If you want a conversation partner, Buildpad. If you want to stop researching and ship, ShipFit. Both solve different problems for different founders. Don't pick on hype.
The smallest version of a product that lets you test a falsifiable hypothesis about a buyer's behavior. Coined by Frank Robinson in 2001; popularized by Eric Ries in 'The Lean Startup' (2011). Not a stripped-down launch product. A learning tool.
Ready to make your next product a success?
9 decisions between your idea and a product worth building.