Whenever you have more candidate features than you can ship in your time window. Most useful at MVP scoping but applicable to any version (V1, V2, sprint planning). The framework is a brutal sorter, not a brainstorming tool.
How to apply MoSCoW
- 1
List every candidate feature without filtering
Get every idea on the table first. Internal team wishlist, customer requests, competitor parity items, your own pet features. Don't prioritize yet. The discipline of MoSCoW depends on starting from a full set, not a pre-curated one.
- 2
Sort each feature into Must / Should / Could / Won't
Must = shipping without this means the version literally cannot deliver its goal. Should = important and high-value, but the version is still usable without it. Could = nice to have, no impact on goal achievement. Won't = explicitly out of scope for this version. The fourth bucket matters: 'Won't' is a commitment, not a deferral.
- 3
Apply the 'cannot ship without' test to every Must
For each feature in Must, ask: if we ship without this, does the version still achieve its goal? If yes, the feature isn't Must. Demote to Should. Most founders fail this test on 50% of their initial Must list. The exercise is the value.
- 4
Cap Must at 60% of capacity
Even after the sorting exercise, your Must list will grow during the build (discovered work, edge cases, integration costs). The DSDM rule of thumb: Must features should consume no more than 60% of your delivery capacity. The remaining 40% absorbs reality. Founders who put 100% of capacity into Must items always ship late.
- 5
Lock the Won't list publicly
Communicate the Won't bucket to your team, your stakeholders, and (if relevant) your customers. The Won't list prevents 'while you're at it' scope creep. If a stakeholder asks for a Won't feature mid-build, the answer is 'V2,' not 'sure, we'll add it.'
Why “everything is a priority” means nothing
The most common scope failure isn’t a missed deadline. It’s a feature list where every item has the same urgency, which is what happens when founders refuse to make the brutal sorting decisions.
The fix: a framework that forces discrete bucketing. Dai Clegg invented MoSCoW at Oracle UK in 1994 for the Dynamic Systems Development Method (DSDM). The original purpose was scoping early-agile software projects under time-box constraints. Twenty years later it’s the default sorter for any kind of work with capacity constraints, which is all kinds of work.
The framework’s discipline isn’t in the buckets. It’s in the test you apply to each item: can we ship this version without this feature? If yes, the feature isn’t Must.
The four buckets
Must have. The version cannot ship without this. Removing the feature breaks the version’s ability to deliver its core goal. For an MVP, Musts are the features that test the central hypothesis. Without them, the test doesn’t run.
Should have. Important, high-value, but the version is still usable without it. Removing the feature degrades the version but doesn’t break it. Shoulds typically ship in V1.1 or V2.
Could have. Nice to have. No impact on goal achievement. These usually accumulate in a parking lot and ship opportunistically when there’s slack in a sprint. Most Coulds never ship.
Won’t have. Explicitly out of scope for this version. The Won’t bucket is what makes MoSCoW different from generic prioritization: it’s a public commitment to NOT do something. Discussions of “could we just add this one thing?” get pointed at the Won’t list.
The 60% rule
Even after honest sorting, your Must list will grow during the build. Discovered work, edge cases, integration costs, polish that turns out to be necessary. The DSDM rule of thumb to absorb this:
Must features should consume no more than 60% of your delivery capacity.
If your team has 8 weeks of capacity, Must items should be 4.8 weeks of estimated work. The remaining 40% absorbs reality. Founders who plan 100% of capacity for Musts always ship late.
This number is empirical. Adjust based on your team’s track record on estimates: if you historically slip by 50%, your Must allocation should be closer to 50%. If you’re unusually accurate, 70% might work. Most teams should start at 60% and recalibrate.
The ‘cannot ship without’ test
Apply this to every candidate Must:
“If we shipped this version WITHOUT this feature, would the version still achieve its goal?”
If yes: not Must. Demote to Should.
If no: Must. It stays.
The test is brutal because most founders, asked off the cuff, would call 50-70% of their initial feature list Musts. Applied honestly, the test usually cuts the Must list by half.
Concrete example. You’re building an MVP to test whether SMB buyers will pay $29/month for an AI-powered email assistant. Initial Must list:
- Email integration (Gmail, Outlook)
- AI summarization
- AI reply suggestions
- Custom templates
- Team collaboration
- Analytics dashboard
- Onboarding flow
- Payment integration (Stripe)
- Mobile app
- API for custom integrations
Apply the test:
- Email integration: without it, the product literally can’t function. Must.
- AI summarization: this is the core value prop. Must.
- AI reply suggestions: useful, but does the hypothesis test require it? If “summarization alone is worth $29/mo” is the hypothesis, this is Should. If “summarization + replies is the bundle” is the hypothesis, Must. Decide.
- Custom templates: nice. Doesn’t test the hypothesis. Should at best, Could realistically.
- Team collaboration: if you’re testing SMB single-user, Won’t. If you’re testing team plans, Must.
- Analytics dashboard: for the BUYER? Should. For the product team (internal)? Must (you can’t measure the hypothesis without it).
- Onboarding flow: do users need it to discover the value? If yes, Must. If the product is self-explanatory, Should.
- Payment integration: required to test willingness to pay. Must.
- Mobile app: SMB email users on desktop don’t need it. Won’t for V1.
- API: V2 territory. Won’t for V1.
End state: 3-5 Musts (email, summarization, payment, maybe replies, maybe onboarding). Everything else moves down or out. Now the V1 spec is scoped.
Won’t is a commitment, not a deferral
The mistake most teams make is treating Won’t as “we’ll get to it later.” That’s not Won’t. That’s Should-with-an-asterisk.
Won’t means: for this version, we are publicly committing not to do this. When a stakeholder asks for it mid-build, the answer is “not in V1; revisit for V2.” The Won’t list goes on a wiki page or wall where everyone can see it.
The discipline matters because scope creep happens through Should-Have items disguised as Musts. The Won’t list closes that backdoor. If a feature is in Won’t, it can’t be re-promoted without an explicit re-scoping conversation.
Re-applying MoSCoW iteratively
MoSCoW isn’t a one-shot exercise. Re-apply it at every version boundary:
- V1 ships. Real user feedback comes in.
- For V1.1: re-sort the Should items from V1 plus new ideas. Apply the “cannot ship without” test against V1.1’s goal (which might be different from V1’s).
- Some Shoulds promote to V1.1’s Must. Some get demoted. Some get reclassified as Won’t because V1 proved they weren’t valuable.
The framework’s value compounds with iteration. Each application sharpens your sense of what truly matters versus what just sounds useful.
Common mistakes
1. Calling everything Must. The default failure mode. If your Must list has 12+ items, you haven’t applied the test honestly.
2. Empty Won’t bucket. If you can’t name 5+ things you’re explicitly not building, you haven’t sorted hard enough.
3. Sorting without a goal. “Must for what?” If V1’s goal isn’t defined, the sort is arbitrary.
4. Letting everyone vote on bucket placement. Founders or product leads decide. Team input on effort estimates is critical. Bucket assignment is a leadership decision.
5. Treating MoSCoW as a brainstorming tool. It’s a sorter. Brainstorm features first (a full list, unfiltered). Then sort. Don’t mix the two phases.
ShipFit and MoSCoW
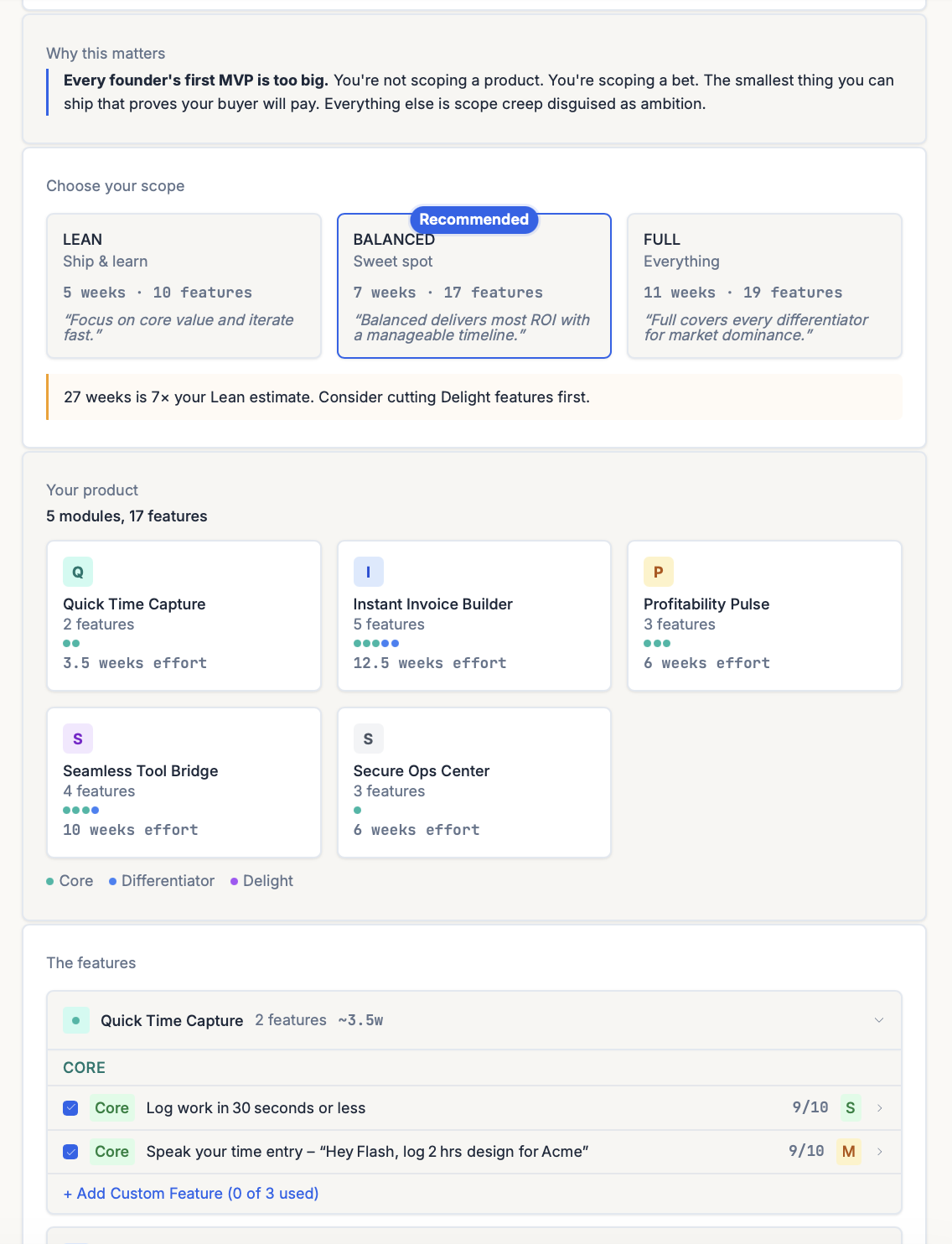
Stage 5 of the ShipFit playbook (What’s V1?) applies MoSCoW:
- You define the V1 goal (the hypothesis V1 tests).
- You list every candidate feature.
- ShipFit applies the ‘cannot ship without’ test to each. Features that fail get demoted automatically.
- ShipFit estimates effort against your team size and warns if Must items exceed 60% of capacity.
- The output is a scoped V1 spec plus a V2 file with the deferred items.
The V2 file isn’t a wishlist. It’s the input for the next MoSCoW pass when V1 ships.
Further reading
- Dai Clegg, original DSDM whitepaper (1994). Hard to find online; mostly cited via DSDM documentation.
- Agile Project Management with DSDM Atern (2014). Practical handbook from the DSDM Consortium.
- Lean Startup validation (Ries, 2011). Provides the “hypothesis V1 tests” framing that MoSCoW needs to be useful.
- ICE scoring. Quantitative version for ranking within the Must list once MoSCoW has done the discrete bucketing.
Common mistakes
- Calling everything a Must because cutting hurts. Forces the Should and Could buckets to be empty, which means the framework isn't doing its job. If your Must list has more than 60% of capacity, you haven't really applied MoSCoW yet.
- Treating Won't as 'maybe later.' Won't is a commitment, not a deferral. If you're not willing to publicly say 'this is not in V1,' you haven't sorted honestly. Won't items go in a V2+ file, not a maybe pile.
- Sorting features without a defined goal for the version. Must/Should/Could only make sense relative to what V1 is trying to prove. If you haven't defined the goal ('test whether SMB buyers will pay $29/mo for X'), the sort is arbitrary.
- Letting the team self-sort. Founders or product leads sort the buckets, ideally with engineering input on effort. If every team member can promote features to Must, the bucket loses meaning.
- Sorting once and never revisiting. MoSCoW is meant to be re-applied at every version boundary (V1.1, V2, V2.5). The Should items from V1 become candidates for V1.1's Must list.
How ShipFit operationalizes this
ShipFit applies MoSCoW in Stage 5 (What's V1?). The stage defines the V1 hypothesis, then runs every candidate feature through the 'cannot ship without' test, producing three MVP packages — Lean, Balanced, Full — with the Must list explicit in each. The Should and Could items get parked in a V2 file with effort tags (S/M/L), so deferred features don't get re-litigated when scope creep hits later.
ShipFit runs 55 frameworks across 9 decision stages
MoSCoW is one tool in a bigger toolkit. The full library covers market sizing, buyer discovery, MVP scoping, pricing, and launch.
The Mom Test
Q3Rob Fitzpatrick
Validation question methodology — real interviews, not theater
Jobs-to-be-Done
Q2-Q4Clayton Christensen
Functional, social, and emotional jobs your product fulfills
7 Powers
Q4Hamilton Helmer
Strategic moats: Scale, Network, Counter-positioning, Switching, Brand, Cornered Resource, Process
Van Westendorp PSM
Q6Feature-weighted price sensitivity analysis without guessing
Blue Ocean Strategy
Q4Kim & Mauborgne
ERRC framework: Eliminate, Reduce, Raise, Create
Fake Door Testing
Q7Pre-build behavioral validation with landing pages and apology modals
+ 49 more: TAM/SAM/SOM Analysis, Porter's Five Forces, Market Timing Analysis, Unit Economics (LTV/CAC)...
Frequently asked questions
What does MoSCoW stand for?
How is MoSCoW different from priority numbers (P0, P1, P2)?
Should the Won't list be public?
What's the difference between MoSCoW and ICE scoring?
Can MoSCoW be used outside software development?
How long should the Must list be?
What happens to Should and Could items after V1 ships?
Keep exploring
The 9-step playbook from market verdict to ship-ready spec.
The Mom Test is Rob Fitzpatrick's framework for customer interviews that generate real signal. Not praise. Three rules, applied step-by-step, with examples.
The Van Westendorp framework uses 4 questions to surface a defensible price range. Here's how to run it, interpret the results, and avoid the usual mistakes.
Most founder market research is a TAM slide that nobody believes. The numbers that actually matter are smaller, harder to defend, and tell you whether the market exists for the ten-customer version of your business.
Most founders confuse idea validation with idea-receiving-encouragement. The two have nothing in common. Here's what real validation looks like, and the four methods that actually produce it.
Does each customer make you money? Or cost you money?
Run nine framework-backed decisions in order before writing code: define the buyer, prove the pain is painful, name the winning angle, scope V1 to the smallest test of the hypothesis, get behavioral evidence (paid pre-orders, signed letters of intent, or credit cards on file from a Fake Door Test), then ship. Most failed startups skipped at least three of those nine. Plan to spend two to four weeks on this. It saves six to nine months of building the wrong thing.
For indie hackers who've wasted months on dead ideas. ShipFit forces 9 decisions before you write a line of code. Proven frameworks, exports to Cursor.
If you want a conversation partner, Buildpad. If you want to stop researching and ship, ShipFit. Both solve different problems for different founders. Don't pick on hype.
Ready to make your next product a success?
9 decisions between your idea and a product worth building.